
Leiden University Centre for Digital Humanities
Small Grants 2025 Research Projects
The LUCDH foster the development of new digital research by awarding a number of Small Grants each year. As in previous years the LUCDH received a large number of excellent grant applications for Research and Personal Development funds. Congratulations to the recipients of this year's research awards!
Small Grants 2025 Research Projects
Nargess Asghari
Despite advances in language technology for spoken languages, sign languages are still left behind. The limited available sign language technology primarily relies on video datasets of (Western) sign languages. The present project explores the possibilities for automatic recognition of signs in print sign language dictionaries.
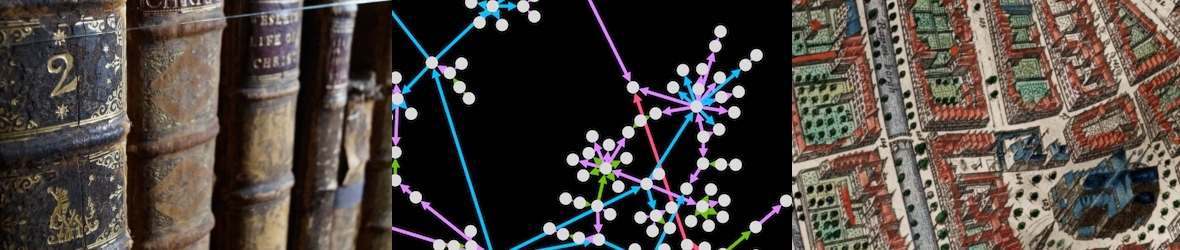
Even though the number of video-based dictionaries is growing, most sign language dictionaries, including historical ones, are in print format. Since sign languages are visual-spatial languages produced dynamically in the 3-dimensional space, their rendition on paper means going from 4D (space and time) to 2D (flat paper). There is no standardised way to represent a sign on paper (eg, the selected ‘state’ of the sign or the camera angle or viewpoint); arrows and other symbols are commonly used to indicate dynamic properties of signs (see examples below).
In this project, we focus on the classification of static images of signs. We will create a labelled dataset of sign images from a representative set of sign language dictionaries. The created dataset will be the first of its kind with still images of lexical signs. We will use out-of-the-box pose estimation models to identify pose keypoints (landmarks) in images. Next, we will train different machine learning models and evaluate their applicability for the intended classification task.
The outcomes of this exploratory project will inform the future development of computational tools for analysing sign language data in various formats. Such tools will facilitate quantitative measurement of lexical variation within and across languages and over time.

Image credits:
(a) Martini, M., & Morgado, M. (2008). Dicionário escolar de Língua Gestual Guineense. Surd'Universo.
(b) & (c) Pélissier, P. (1856). Iconographie des signes: faisant partie de l'enseignement primaire des sourds-muets. Paris: Imprimerie et libraire de Paul Dupont
Sjef Barbiers, Irina Morozova & Stephan Raaijmakers
There are languages with and without determiners, i.e. function words such as a and the in English. Native speakers of determiner languages like Dutch and English know intuitively when a syntactic/semantic/pragmatic context requires a determiner to be present or absent, and whether it should be definite or indefinite. On the other hand, it is very hard for L1 speakers of a determinerless language such as Russian to learn the correct use of determiners even if they are highly proficient L2 speakers of the determiner language. The linguistic conditions for the correct use of determiners are very complex and have not been described and understood in full. This pilot project concentrates on two descriptive questions (1,2), and two methodological questions involving computational tools (3,4):
- What kind of determiner use patterns does an L2 speaker of English and Dutch with Russian as an L1 show?
- What is the role of L1 transfer in these patterns?
- What traditional NLP-methods (tagging, parsing) are most suitable for automatic extraction of determiner errors?
- How can we use recent Large Language Models (LLMs) as tools for the detection and repair of determiner errors in both languages?

Carmen van den Bergh
Among the many texts housed in a literary repository, such as archives and special collections, it is the genre of the letter that offers us a candid glimpse into the inner workings of the creative mind of the sender. The genre remains, until today, largely understudied in the literary field and there are many reasons for this negligence, from a low editorial prestige to accessibility. (Douglas 2013)
A number of factors that complicated research of archival letters until recently, have been made less decisive with the entrance of modern technologies and the still evolving field of DH. Letters are now easier to access and to preserve. Deciphering difficult-to-read writings is made faster by increasingly sophisticated OCR software and more archives are willing to participate in digitization projects. Unfortunately, many literature scholars are still deterred from using DH in their research, often due to high costs of tools, out of fear of not being able to do it, or lack of time to delve into the matter. (Willaert, Speelman, Truyen 2018). Also, researchers are often asked to be multilingual. And this specialist knowledge of languages is becoming less evident, in a period of budget cuts.
We don’t have to look far in foreign archives to find real gems. Our own Special Collections at Leiden University Library have a treasure trove of letters from prominent people (writers, philosophers, intellectuals, botanists, kings and popes) who sought contact with Dutch professors. The letters are written in Latin, in German, in French, in Italian. The use of AI tools such as Transkribus and Omeka is not intended to undermine or replace the work of the researcher, but can help the researcher to accelerate and automate certain processes (such as handwriting recognition, extrapolation of metadata and transcribing the letters in multiple languages), thus leaving more time for content analysis, giving modern-day scholars the chance to recreate and study the networks of epistolary exchanges between European and Dutch courts, notables and contacts throughout time.
Tian Yang & Susana Valdez
As global migration increases, healthcare systems face increasing challenges in overcoming language barriers between providers and migrant patients with limited proficiency. These barriers significantly hinder access to healthcare services, often leading to health inequality. Recent technological advancements have introduced machine translation (MT) tools like Google Translate (GT) as cost-effective, accessible alternatives to traditional solutions such as professional and ad-hoc interpreters. MT tools are increasingly used to access medical information, translate documents, schedule appointments, and facilitate communication during consultations. Despite their potential, concerns persist regarding accuracy, cultural nuance, data privacy, and trust in MT tools within healthcare. Research is needed to explore users' perceptions in MT to assess its effectiveness and limitations in bridging language gaps in healthcare. These insights will help refine MT tools to address the complexities of medical communication, ultimately improving healthcare outcomes and promoting equitable healthcare.
This study will recruit 12 Chinese migrant patients with limited English proficiency, along with their general practitioners (GPs), who will provide consent to participate. All patients will use Google Translate as needed during their diagnostic process.
- Observations will be conducted during consultations, focusing on communication effectiveness, challenges encountered, and how GT is integrated into the consultation.
- Semi-structured interviews with patients and GPs will explore their perceptions of GT, including comprehension, usability, challenges, concerns, and trust.
- Questionnaires will assess user satisfaction, comfort, and the perceived effectiveness of GT in medical consultations.
